
How to Register a Custom LLM in Langchain: Step-by-Step Guide
This tutorial provides a step-by-step guide to register a custom Large Language Model (LLM) in Langchain using the CustomH2OGPTE class. We’ll cover setup, building the custom LLM wrapper, and testing with detailed code snippets and explanations.
1. Prerequisites to Register Custom LLM in Langchain
Requirements:
- Python installed on your system
- API Key and URL for the H2OGPTE model stored securely in
config.storage - Required Libraries:
pip install langchain-community==0.3.18 langchain-core==0.3.40 langchain experimental==0.3.4 langchain-openai==0.3.7 h2ogpte==1.6.22H2OGPTE Setup:
- Follow the H2OGPTE Documentation for setup instructions.
- Obtain an API Key and configure the URL for the H2OGPTE endpoint.
- Store your credentials securely in
config.storage.
2. Creating a Custom LLM Wrapper Class
We’ll create a custom wrapper class (CustomH2OGPTE) by extending Langchain’s LLM class. This class acts as a bridge between Langchain and the H2OGPTE model.
Code: CustomH2OGPTE Class
from typing import Any, Dict, List, Optional
from langchain_core.language_models.llms import LLM
from h2ogpte import H2OGPTE
from config import storage
class CustomH2OGPTE(LLM):
"""A custom LLM wrapper for the H2OGPTE model to be used within LangChain."""
api_key: str = storage.get("h2ogpte_key")
url: str = storage.get("h2ogpte_url")
client: H2OGPTE = H2OGPTE(address=url, api_key=api_key)
model_name: str = "gpt-4o"
temperature: float = 0.0
top_k: int = 1
top_p: float = 1.0
repetition_penalty: float = 1.07
max_new_tokens: int = 1024
min_max_new_tokens: int = 512
response_format: str = "text"
def get_llms(self) -> List[str]:
"""Returns a list of available model names from the H2OGPTE client."""
return [x["base_model"] for x in self.client.get_llms()]
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
**kwargs: Any,
) -> str:
"""Generate a response using the H2OGPTE client."""
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
response = self.client.answer_question(
question=prompt,
llm=self.model_name,
llm_args={
"temperature": self.temperature,
"top_k": self.top_k,
"top_p": self.top_p,
"repetition_penalty": self.repetition_penalty,
"max_new_tokens": self.max_new_tokens,
"min_max_new_tokens": self.min_max_new_tokens,
"response_format": self.response_format,
}
)
return response.content
@property
def _identifying_params(self) -> Dict[str, Any]:
"""Returns the parameters identifying the LLM configuration."""
return {
"model_name": self.model_name,
"temperature": self.temperature,
"top_k": self.top_k,
"top_p": self.top_p,
"repetition_penalty": self.repetition_penalty,
"max_new_tokens": self.max_new_tokens,
"response_format": self.response_format,
}
@property
def _llm_type(self) -> str:
"""Returns the type of the LLM."""
return "h2ogpte"Reference ~ https://python.langchain.com/docs/how_to/custom_llm/
3. Testing the Custom LLM Wrapper
Testing ensures the custom LLM functions as expected in different scenarios. Each test is provided as a separate step for clarity.
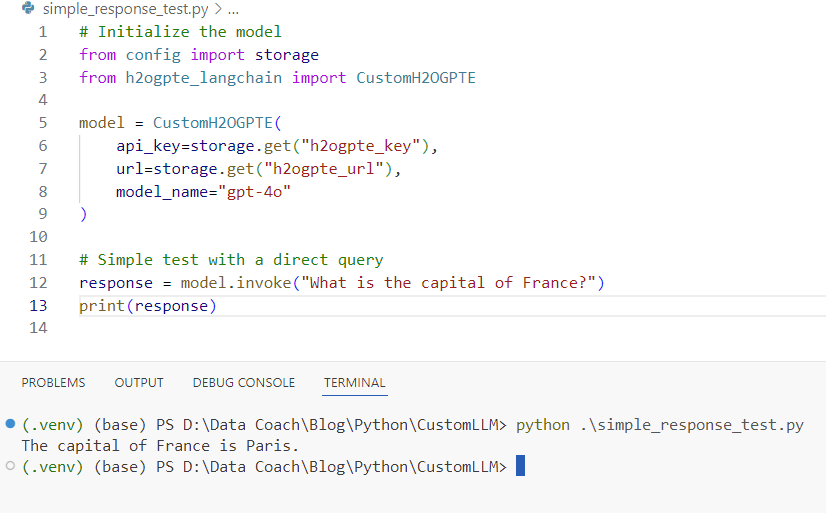
Step 1: Simple Response Test
This test verifies that the CustomH2OGPTE model can generate a response to a basic query.
# Initialize the model
from config import storage
from h2ogpte_langchain import CustomH2OGPTE
model = CustomH2OGPTE(
api_key=storage.get("h2ogpte_key"),
url=storage.get("h2ogpte_url"),
model_name="gpt-4o"
)
# Simple test with a direct query
response = model.invoke("What is the capital of France?")
print(response)Output
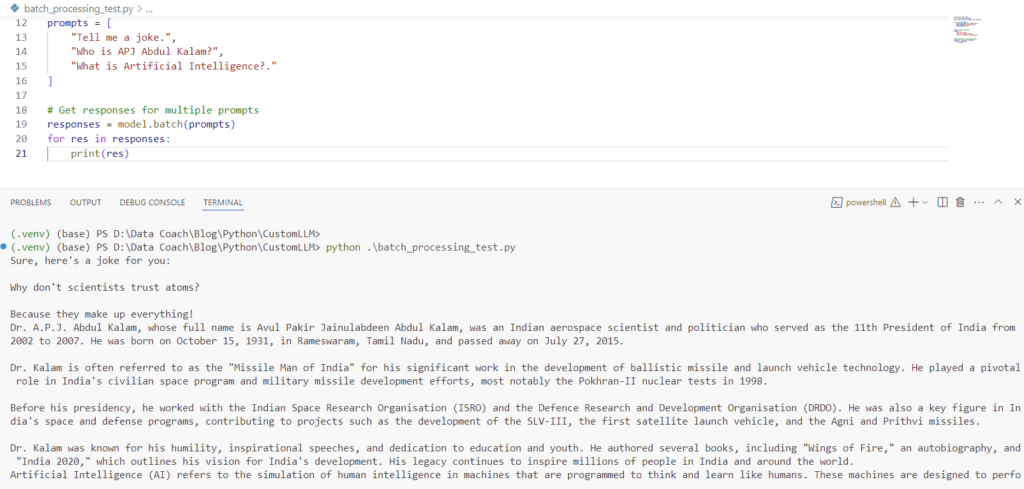
Step 2: Batch Processing Test
This test ensures the model can handle multiple prompts simultaneously using the batch method.
# Batch prompt invocation
prompts = [
"Tell me a joke.",
"Who is APJ Abdul Kalam?",
"What is Artificial Intelligence?."
]
# Get responses for multiple prompts
responses = model.batch(prompts)
for res in responses:
print(res)Output
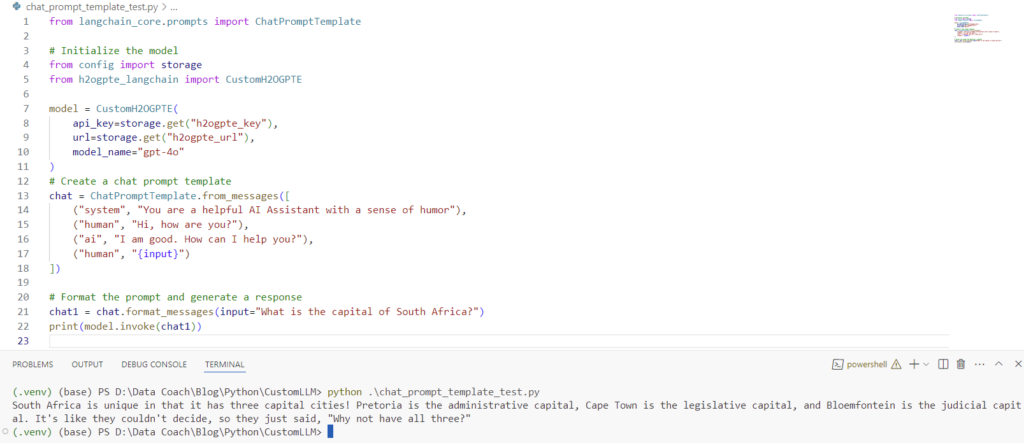
Step 3: Langchain Tool Integration Test
This test demonstrates the integration of CustomH2OGPTE with Langchain tools, specifically ChatPromptTemplate.
from langchain_core.prompts import ChatPromptTemplate
# Create a chat prompt template
chat = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI Assistant with a sense of humor"),
("human", "Hi, how are you?"),
("ai", "I am good. How can I help you?"),
("human", "{input}")
])
# Format the prompt and generate a response
chat1 = chat.format_messages(input="What is the capital of South Africa?")
print(model.invoke(chat1))Output
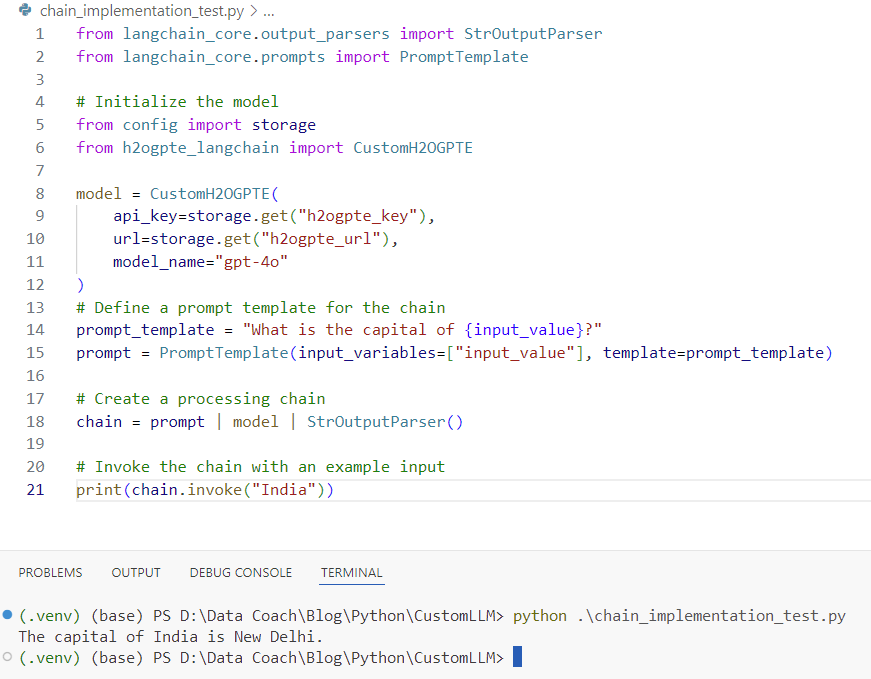
Step 4: Chain Implementation Test
This test shows how to use the model within a Langchain chain, combining prompt templates and output parsers.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# Define a prompt template for the chain
prompt_template = "What is the capital of {input_value}?"
prompt = PromptTemplate(input_variables=["input_value"], template=prompt_template)
# Create a processing chain
chain = prompt | model | StrOutputParser()
# Invoke the chain with an example input
print(chain.invoke("India"))Output
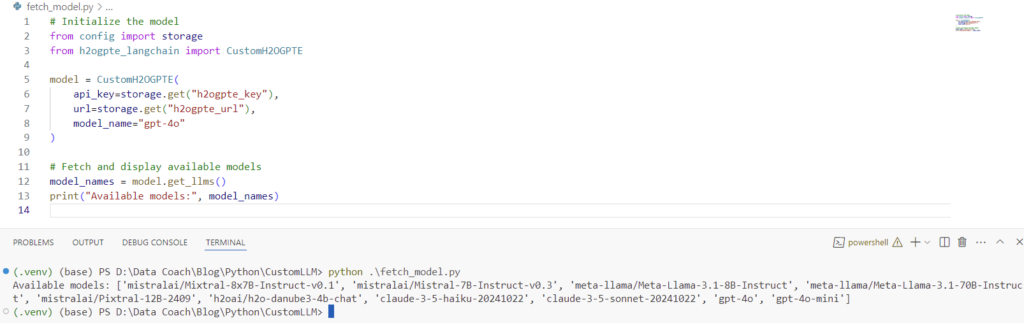
Step 5: Fetching Available Models Test
This test checks if the get_llms method correctly retrieves the list of available models from the H2OGPTE client.
# Fetch and display available models
model_names = model.get_llms()
print("Available models:", model_names)Output
GitHub Repository Link: https://github.com/data-coach/register-custom-llm-langchain.git
Conclusion
Following these detailed steps, you can successfully register and use a custom LLM in Langchain with the CustomH2OGPTE class. Each test case demonstrates the versatility and robustness of the integration, whether for simple queries, batch processing, or advanced chaining and tool integration.
If you encounter any issues or have questions, feel free to ask using this link!
Learn how to seamlessly register a custom LLM in Langchain with our detailed step-by-step guide. Discover how to create a custom wrapper class, integrate H2OGPTE, and run comprehensive test cases for powerful and flexible LLM integrations.
Comments